我们在做普通功能开发的时候有设计模式作为指导,提供了开发过程中面临的一般问题的解决方案;那么我们在致力于提高系统吞吐量的时候,有没有一些通用解决方案呢?是的,那就是并发模型,由于并发模型类似于分布式系统架构,因此它们通常可以互相借鉴思想,接下来就让我们来一起学习并发模型,并思考如何扩展到分布式系统架构。
并发模型指定了系统中的线程如何通过协作来完成分配给它们的作业,不同的并发模型采用不同的方式拆分作业,同时线程间的协作和交互方式也不相同,接下来本文就简单介绍几种并发模型。
¶并行工作者
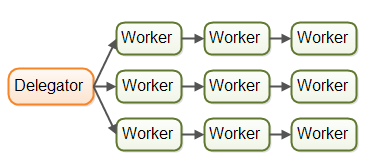
在并行工作者模型中,委派者(Delegator)将传入的作业分配给不同的工作者。每个工作者完成整个任务,工作者们并行运作在不同的线程上,甚至可能在不同的CPU上。并行工作者模型如下图所示:
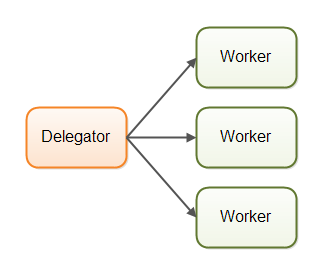
这就好比电话接线员一样, 收到的每一个电话投诉或者业务处理请求,都会提交对应的工单, 然后交由对应的工作人员来处理。
在Java应用系统中,并行工作者模型是最常见的并发模型。java.util.concurrent包中的许多并发实用工具都是设计用于这个模型的。这里以线程池为例:
1 | // ThreadPoolExecutor 就是作为Delegator |
¶并行工作者模型的优点
并行工作者模式的优点是,它很容易理解,你只需添加更多的工作者来提高系统的并行度。在我们常使用的J2EE应用服务器的设计中能看到这个模型的踪迹,我们以jetty为例(不知道jetty内部如何实现?没关系),我们先dump下线程日志,找到http线程:
1 | "qtp1428842218-222" prio=5 tid=0x00000000000000de nid=0x74667b27 waiting on condition <0x000000002da5bbe7> [0x0000000074667b27] cpu=[total=0ms,user=0ms] |
org.eclipse.jetty.util.thread.QueuedThreadPool源码在jetty-util包中,核心代码如下:
1 | private Runnable _runnable = new Runnable() { |
其中SelectChannelEndPoint就是每个job,想要增加服务器的吞吐量,最简单的方法只要增加worker就好了。
¶并行工作者模型的缺点
¶共享状态可能会很复杂
在实际应用中,并行工作者模型可能比前面所描述的情况要复杂得多。共享的工作者经常需要访问一些共享数据,无论是内存中的或者共享的数据库中的。下图展示了并行工作者模型是如何变得复杂的:
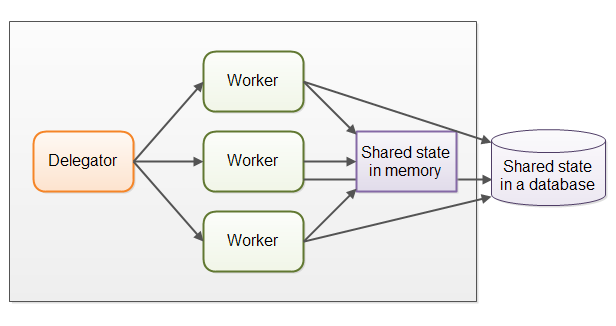
有些共享状态是在像作业队列这样的通信机制下。但也有一些共享状态是业务数据,数据缓存,数据库连接池等。
一旦共享状态潜入到并行工作者模型中,将会使情况变得复杂起来。线程需要以某种方式存取共享数据,以确保某个线程的修改能够对其他线程可见(数据修改需要同步到主存中,不仅仅将数据保存在执行这个线程的CPU的缓存中)
¶无状态的工作者
共享状态能够被系统中得其他线程修改。所以工作者在每次需要的时候必须重读状态,以确保每次都能访问到最新的副本,不管共享状态是保存在内存中的还是在外部数据库中。工作者无法在内部保存这个状态(但是每次需要的时候可以重读)称为无状态的。
每次都重读需要的数据,将会导致速度变慢,特别是状态保存在外部数据库中的时候。
¶任务顺序是不确定的
并行工作者模式的另一个缺点是,作业执行顺序是不确定的。无法保证哪个作业最先或者最后被执行。作业A可能在作业B之前就被分配工作者了,但是作业B反而有可能在作业A之前执行。
并行工作者模式的这种非确定性的特性,使得很难在任何特定的时间点推断系统的状态。这也使得它也更难(如果不是不可能的话)保证一个作业在其他作业之前被执行。
¶流水线(Worker-Thread)
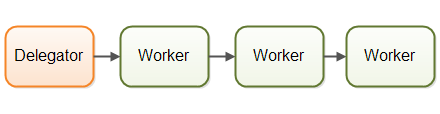
Worker-Thread 模式也称为流水线设计模式, 这种设计模式类似于工厂流水线, 上游工作人员完成了某个产品的组装之后, 将半成品放到流水线传送带上, 接下来的加工工作则会交给下游的工人, 如下图所示:

每个工作者只负责作业中的部分工作,当完成了自己的这部分工作时工作者会将作业转发给下一个工作者。每个工作者在自己的线程中运行,并且不会和其他工作者共享状态,流水线模型如下图所示:
在实际应用中,作业有可能不会沿着单一流水线进行。由于大多数系统可以执行多个作业,作业从一个工作者流向另一个工作者取决于作业需要做的工作。在实际中可能会有多个不同的虚拟流水线同时运行。这是现实当中作业在流水线系统中可能的移动情况:
¶响应式
采用流水线并发模型的系统有时候也称为反应器系统或事件驱动系统,系统内的工作者对系统内出现的事件做出响应,这些事件也有可能来自于外部世界或者发自其他工作者。事件可以是传入的HTTP请求,也可以是某个文件成功加载到内存中等。
以上面的流水线为例,流水线上的每个工作者的工作效率可能不一样,不同阶段作业的耗时可能也不一样,我们就可以对作业进行分类,根据实际情况为每类作业分配不同数量的工作者。对上面的流水线做一下调整,工作者之间不直接进行通信,相反,它们在不同的通道中发布自己的消息(事件),其他工作者们可以在这些通道上监听消息,发送者无需知道谁在监听。
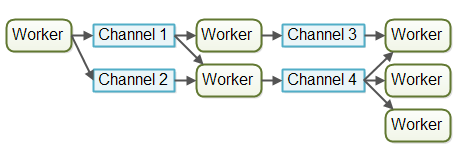
比如我们到饭店吃饭,从点菜到上菜,将中间整个过程当做流水线,worker的实现如下:
1 | public class Worker extends Thread{ |
每个Worker不需要知道下一个步骤具体是什么,只需要往指定的channel中发布自己的消息,Worker的使用如下:
1 |
|
¶流水线模型的优点
¶无需共享状态
工作者之间无需共享状态,意味着实现的时候无需考虑所有因并发访问共享对象而产生的并发性问题。这使得在实现工作者的时候变得非常容易。在实现工作者的时候就好像是单个线程在处理工作-基本上是一个单线程的实现。
¶有状态的工作者
当工作者知道了没有其他线程可以修改它们的数据,工作者可以变成有状态的。对于有状态,我是指,它们可以在内存中保存它们需要操作的数据,只需在最后将更改写回到外部存储系统。因此,有状态的工作者通常比无状态的工作者具有更高的性能。
¶较好的硬件整合(Hardware Conformity)
单线程代码在整合底层硬件的时候往往具有更好的优势。首先,当能确定代码只在单线程模式下执行的时候,通常能够创建更优化的数据结构和算法。
其次,像前文描述的那样,单线程有状态的工作者能够在内存中缓存数据。在内存中缓存数据的同时,也意味着数据很有可能也缓存在执行这个线程的CPU的缓存中。这使得访问缓存的数据变得更快。
¶合理的作业顺序
基于流水线并发模型实现的并发系统,在某种程度上是有可能保证作业的顺序的。作业的有序性使得它更容易地推出系统在某个特定时间点的状态。更进一步,你可以将所有到达的作业写入到日志中去。一旦这个系统的某一部分挂掉了,该日志就可以用来重头开始重建系统当时的状态。按照特定的顺序将作业写入日志,并按这个顺序作为有保障的作业顺序。下图展示了一种可能的设计:
实现一个有保障的作业顺序是不容易的,但往往是可行的。如果可以,它将大大简化一些任务,例如备份、数据恢复、数据复制等,这些都可以通过日志文件来完成。
¶流水线模式的缺点
流水线并发模型最大的缺点是作业的执行往往分布到多个工作者上,甚至分不到多个不同机器上的工作者上。这样导致在追踪某个作业到底被什么代码执行时变得困难。
¶Producer-Consumer
Producer 是“ 生产者" 的意思, 指的是生成数据的线程。Consumer 则是“ 消费者” 的意思, 指的是使用数据的线程。
生产者安全地将数据交给消费者。虽然仅是这样看似简单的操作, 但当生产者和消费者以不同的线程运行时, 两者之间的处理速度差异便会引起问题。例如, 消费者想要获取数据, 可数据还没生成, 或者生产者想要交付数据, 而消费者的状态还无法接收数据等。
Producer-Consumer 模式在生产者和消费者之间加入了一个“ 桥梁角色” ,该桥梁角色用于消除生产者和消费者线程之间处理速度的差异,该模型如下图所示:
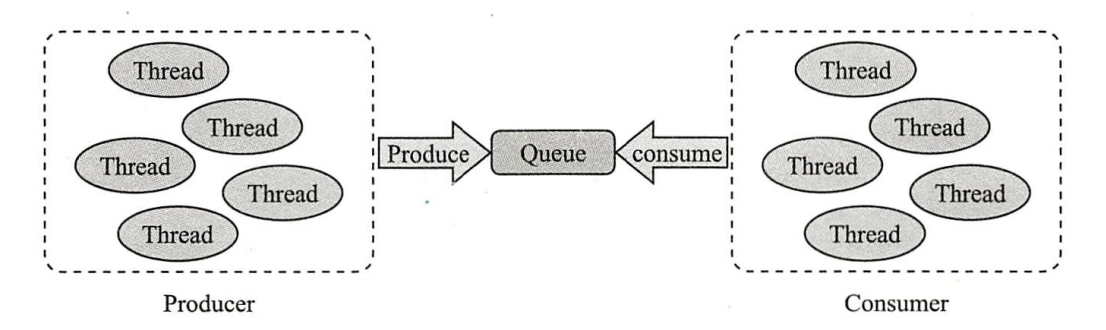
在某种特殊情况,Producer和Consumer都只有一个的情况,是不是就变成流水线模型了。
¶Fork-Join
在必要的情况下,将一个大任务,进行拆分(fork) 成若干个子任务(拆到不能再拆,这里就是指我们制定的拆分的临界值),再将一个个小任务的结果进行join汇总。,也就是分治思想,如下图所示:
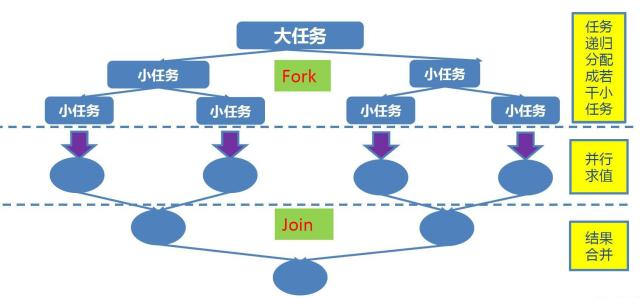
MapReduce
输入一个大,通过Split之后,将其分为多个片
每个文件分片由单独的机器去处理,这就是map方法
将各个机器计算的结果进行汇总并得到最终的结果,这就是reduce方法
Fork/Join采用“工作窃取模式”,当执行新的任务时他可以将其拆分成更小的任务执行,并将小任务加到线程队列中,然后再从一个随即线程中偷一个并把它加入自己的队列中。
就比如两个CPU上有不同的任务,这时候A已经执行完,B还有任务等待执行,这时候A就会将B队尾的任务偷过来,加入自己的队列中,对于传统的线程池,ForkJoin更有效的利用的CPU资源!
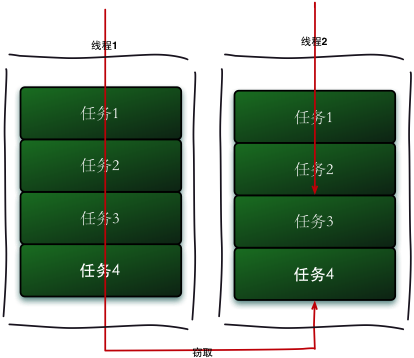
jdk1.7提供了Fork-Joink框架:ForkJoinPool,要使用ForkJoin框架,必须首先创建一个ForkJoin任务。它提供在任务中执行fork()和join()操作的机制,通常情况下我们不需要直接继承ForkJoinTask类,而只需要继承它的子类,Fork/Join框架提供了以下两个子类:
- RecursiveAction:用于没有返回结果的任务。
- RecursiveTask :用于有返回结果的任务。
1 | public class ForkJoinWork extends RecursiveTask<Long> { |
接下来对比下:ForkJoin实现、单线程计算、Java 8 并行流的实现
1 | public class ForkJoinPoolTest { |
¶产考文献
- 《图解Java多线程设计模式》
- 《Java高并发编程详解:多线程与架构设计》
- http://ifeve.com/并发编程模型