之前我们了解了线程的基础知识,那么多个线程一起运行的时候,难免会操作同一个资源。从上一讲里面我们了解到每个线程会有自己的缓存,那么多个线程操作同一个资源的时候,怎么保证资源操作结果的正确性。这些问题,其实从JDK1.5起已经提供了解决方案,接下来就让我们一起来看看java.util.concurrent。
首先我们来看一个经典问题:i++是否线程安全?
1 | static class AddTest{ |
运行结果i会是多少呢,有可能:i = 98、i = 99、i = 100,为什么会出现这样的结果呢?
volatile只能保证可见性,并不能保证原子性,表达式i++操作步骤分解如下:
1、从主存取出i的值放到线程栈
2、在线程栈中计算i+1的值
3、将i+1的值写到主存中的变量i
很不幸的是,这几个操作并不是原子性的,如果多个同时进行i++操作,就会出现线程安全问题。
1、获取–> 线程A:i=1,线程B:i=1
2、计算–> 线程A:i+1=2,线程B:i+1=2
3、回写–> 线程A:i=2,线程B:i=2
¶原子类(Atomic)
要保证i++的线程安全,加上synchronized关键字即可:
1 | static class AddTest{ |
这下不管运行多少次i的结果都是100,不信的可以尝试一下。
在java.util.concurrent.atomic提供了原子类,解决i++也可以使用AtomicInteger,如下所示:
1 |
|
那么AtomicInteger是怎么保证线程安全的呢,让我们看看getAndIncrement方法,:
1 | public final int getAndIncrement() { |
Unsafe类只能由jdk源码使用,否则会抛出异常:java.lang.SecurityException: Unsafe
jdk中提供的原子类如下:
-
AtomicBoolean保证布尔值的原子性 -
AtomicInteger保证整型的原子性 -
AtomicLong保证长整型的原子性 -
AtomicIntegerArray保证整型数组的原子性 -
AtomicLongArray保证长整型数组原子性 -
AtomicIntegerFieldUpdater保证整型的字段更新 -
AtomicLongFieldUpdater保证长整型的字段更新 -
AtomicReferenceArray保证引用数组的原子性 -
AtomicReferenceFieldUpdater保证引用类型的字段更新 -
AtomicStampedReference可以解决CAS的ABA问题,类似提供版本号 -
AtomicMarkableReference可以解决CAS的ABA问题,提供是或否进行判断
¶锁(Lock)
¶简单锁实现
上一讲我们讲到线程间通信,在这里我们实现一个简单的锁。
1 | static class SimpleLock { |
这个锁存在什么问题呢,可重入?公平性?
¶ReentrantLock
除了使用synchronized关键字保证线程安全之外,还能够使用java.util.concurrent.locks包中所提供的Lock,先来看一个简单的例子吧。
1 | private int instanceNum; |
不加lock的时候输出:
1 | a set num is 100! |
加上lock之后,只有等一个线程执行完之后,另一个线程才能进入:
1 | a set num is 100! |
¶ReentrantReadWriteLock
如果我们对资源的读取比较频繁,而修改相对较少,使用前面提到的锁有什么弊端呢,两个线程同时读取资源需要加锁吗?
ReadWriteLock就是读写锁,它是一个接口,ReentrantReadWriteLock实现了这个接口。可以通过readLock()获取读锁,只要没有线程拥有写锁(writers==0),且没有线程在请求写锁(writeRequests ==0),所有想获得读锁的线程都能成功获取。
通过writeLock()获取写锁,当一个线程想获得写锁的时候,首先会把写锁请求数加1(writeRequests++),然后再去判断是否能够真能获得写锁,当没有线程持有读锁(readers==0 ),且没有线程持有写锁(writers==0)时就能获得写锁。有多少线程在请求写锁并无关系。
简单说就是:
- 读读共享
- 写写互斥
- 读写互斥
- 写读互斥
¶AQS(AbstractQueuedSynchronizer)
锁分为“公平锁”和“非公平锁”,顾名思义:
- 公平锁:线程获取锁的顺序是按照线程加锁的顺序来分配的,FIFO。
- 非公平锁:是一种获取锁的抢占机制,是随机获得锁的,先来的不一定先得到锁,可能导致某些线程一直拿不到锁。
1 | public ReentrantLock() { |
其中FairSyncAQS和NonfairSync继承ReentrantLock.Sync和ReentrantReadWriteLock.Sync,而他们都是AbstractQueuedSynchronizer(简称AQS)的子类。AQS是基于FIFO队列实现的,AQS整个类中没有任何一个abstract的抽象方法,取而代之的是,需要子类去实现的那些方法通过一个方法体抛出UnsupportedOperationException异常来让子类知道,告知如果没有实现这些方法,则直接抛出异常。
| 方法名 | 方法描述 |
|---|---|
| tryAcquire | 以独占模式尝试获取锁,独占模式下调用acquire,尝试去设置state的值,如果设置成功则返回,如果设置失败则将当前线程加入到等待队列,直到其他线程唤醒 |
| tryRelease | 尝试独占模式下释放状态 |
| tryAcquireShared | 尝试在共享模式获得锁,共享模式下调用acquire,尝试去设置state的值,如果设置成功则返回,如果设置失败则将当前线程加入到等待队列,直到其他线程唤醒 |
| tryReleaseShared | 尝试共享模式下释放状态 |
| isHeldExclusively | 是否是独占模式,表示是否被当前线程占用 |
这里以ReentrantLock的公平锁来举例,看一下AQS内部是如何实现锁的获取和释放。
1 | // ReentrantLock.FairSync |
AQS只提供固定的方法给子类实现,就可以实现不同的功能,这个满足设么类设计原则,那么又使用了什么设计模式?
¶同步工具
¶CountDownLatch:减法计数器
countDown() 执行一次计数器减一,await() 等待计数器停止,唤醒其他线程,示例如下:
1 | public class CountDownLatchTest { |
¶CyclicBarrier:加法计数器
await()执行一次计数器加一,执行次数完成后,再执行CyclicBarrier的Runnable,示例如下:
1 | public class TestCyclicBarrier { |
countDownLatch是一个计数器,线程完成一个记录一个,计数器递减,只能只用一次。
CyclicBarrier的计数器更像一个阀门,需要所有线程都到达,然后继续执行,计数器递增,提供reset功能,可以多次使用。
¶Semaphore:计数信号量
实际开发中主要用来做限流操作,即限制可以访问某些资源的线程数量。
- 初始化
- 获取许可
- 释放许可
1 | public class SemaphoreTest { |
¶Exchanger:数据交换
Exchanger 是 JDK 1.5 开始提供的一个用于两个工作线程之间交换数据的封装工具类,简单说就是一个线程在完成一定的事务后想与另一个线程交换数据,则第一个先拿出数据的线程会一直等待第二个线程,直到第二个线程拿着数据到来时才能彼此交换对应数据。
1 | public class ExchangerTest { |
¶并发容器
一起来回想下,java中的容器有哪几种,List、Set、Queue、Map?
大家熟知的这些集合类ArrayList、HashSet、HashMap这些容器都是非线程安全的。
比如Vector、Stack、Hashtable以及Collections.synchronized等方法生成的容器都是线程安全的,通过查看源码可以知道这些容器都在需要同步的方法上加上了synchronized关键字,在高并发的情况下容器的吞吐量就会降低,为了解决性能问题就有了并发容器。
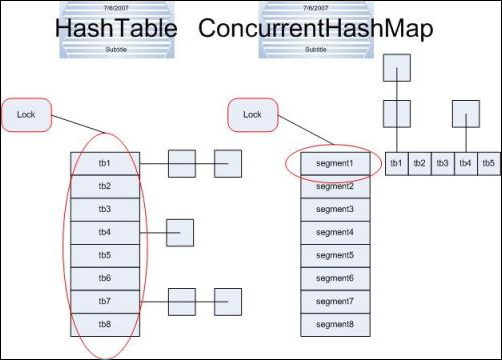
¶ConcurrentHashMap
对应的非并发容器:HashMap
目标:代替Hashtable、synchronizedMap,支持复合操作
原理:JDK6中采用一种更加细粒度的加锁机制Segment“分段锁”,JDK8中采用CAS无锁算法。
¶CopyOnWriteArrayList
对应的非并发容器:ArrayList
目标:代替Vector、synchronizedList
原理:利用高并发往往是读多写少的特性,对读操作不加锁,对写操作,先复制一份新的集合,在新的集合上面修改,然后将新集合赋值给旧的引用,并通过volatile 保证其可见性,当然写操作的锁是必不可少的了。
¶CopyOnWriteArraySet
对应的非并发容器:HashSet
目标:代替synchronizedSet
原理:基于CopyOnWriteArrayList实现,其唯一的不同是在add时调用的是CopyOnWriteArrayList的addIfAbsent方法,其遍历当前Object数组,如Object数组中已有了当前元素,则直接返回,如果没有则放入Object数组的尾部,并返回。
¶ConcurrentSkipListMap
对应的非并发容器:TreeMap
目标:代替synchronizedSortedMap(TreeMap)
原理:Skip list(跳表)是一种可以代替平衡树的数据结构,默认是按照Key值升序的。
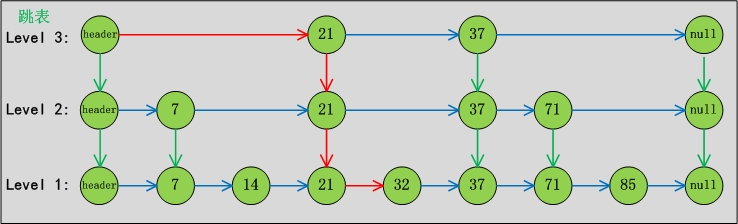
跳表分为许多层(level),每一层都可以看作是数据的索引,这些索引的意义就是加快跳表查找数据速度。每一层的数据都是有序的,上一层数据是下一层数据的子集,并且第一层(level 1)包含了全部的数据;层次越高,跳跃性越大,包含的数据越少。
跳表包含一个表头,它查找数据时,是从上往下,从左往右进行查找。
¶ConcurrentSkipListSet
对应的非并发容器:TreeSet
目标:代替synchronizedSortedSet
原理:内部基于ConcurrentSkipListMap实现。
¶ConcurrentLinkedQueue
不会阻塞的队列
对应的非并发容器:Queue
原理:基于链表实现的FIFO队列,CAS实现线程安全
¶BlockingQueue
特点:拓展了Queue,增加了可阻塞的插入和获取等操作
原理:通过ReentrantLock实现线程安全,通过Condition实现阻塞和唤醒
实现类:
- LinkedBlockingQueue:基于链表实现的可阻塞的FIFO队列
- LinkedBlockingDeque:基于链表实现的可阻塞的双端队列
- ArrayBlockingQueue:基于数组实现的可阻塞的FIFO队列
- PriorityBlockingQueue:按优先级排序的队列
- SynchronousQueue:只有一个元素的队列
¶线程池(ThreadPool)
在面向对象编程中,创建和销毁对象是很费时间的,因为创建一个对象要获取内存资源或者其它更多资源。
在Java中虚拟机将试图跟踪每一个对象,以便能够在对象销毁后进行垃圾回收。所以提高服务程序效率的一个
手段就是尽可能减少创建和销毁对象的次数,特别是一些很耗资源的对象创建和销毁。
如何利用已有对象来服务就是一个解决的关键问题,这也就是"池化资源"技术产生的原因。
线程池是一种多线程处理形式,处理过程中将任务添加到队列,然后在创建线程后自动启动这些任务。
线程是稀缺资源,使用线程池可以减少创建和销毁线程的次数,每个工作线程都可以重复使用。
可以根据系统的承受能力,调整线程池中工作线程的数量,防止因为消耗过多内存导致服务器崩溃。
一个线程池包括以下四个基本组成部分:
- 线程池管理器(ThreadPool):用于创建并管理线程池,包括创建线程池、销毁线程池,添加新任务;
- 工作线程(PoolWorker):线程池中线程,在没有任务时处于等待状态,可以循环的执行任务;
- 任务接口(Task):每个任务必须实现的接口,以供工作线程调度任务的执行,它主要规定了任务的入口,任务执行完后的收尾工作,任务的执行状态等;
- 任务队列(taskQueue):用于存放没有处理的任务。提供一种缓冲机制。
详细内容请点:线程池详解
¶产考文献
-
https://fanzhongwei.com/mutlithreading/thread-pool.html
-
《深入Java虚拟机:JVM高级特性与最佳实践(第2版)》